
The gift of sight: computer vision
Written by Aaron Hammond
04.20.2023
Before we can detect any immunization records, we need to preprocess the document. This includes a few steps:
- Convert each upload into a common file format (PDF)
- Tokenize the raw contents of the file and segment characters to locate words on the page
- Extract text from the document into a human-readable form
Conversion
We accept documents in almost every file format to keep things easy for parents and nurses. This includes common image formats but also outliers like Word, Powerpoint, and even HTML files.
Writing code to handle all these different formats is challenging. If we want to show the user a preview of the file they just uploaded, our engineers would need to write code telling the browser how to do so for JPG, PNG, and GIF files. Other formats that work well on desktops, like DOCX, are even more challenging or impossible to display in a browser. To keep everything tidy, we instead isolate and separate this concern or aspect of the problem to address the challenge once rather than piece-by-piece over time.
Before any parsing or “reading” occurs, we first convert whatever files the user provides into one standard format. With portability as our chief concern, PDF (or Portable Document Format) was a natural choice. PDFs are commonly accepted as input into other systems, and most folks today are comfortable working with them.
Tokenization
We visually tokenize the document using techniques from two branches of machine learning called Computer Vision (or CV) and Natural Language Processing (or NLP).The system scans the picture to identify regions in the image that likely contain chunks of text or tokens. Typically, these tokens correspond directly to the discrete words within the document, with a token per word.
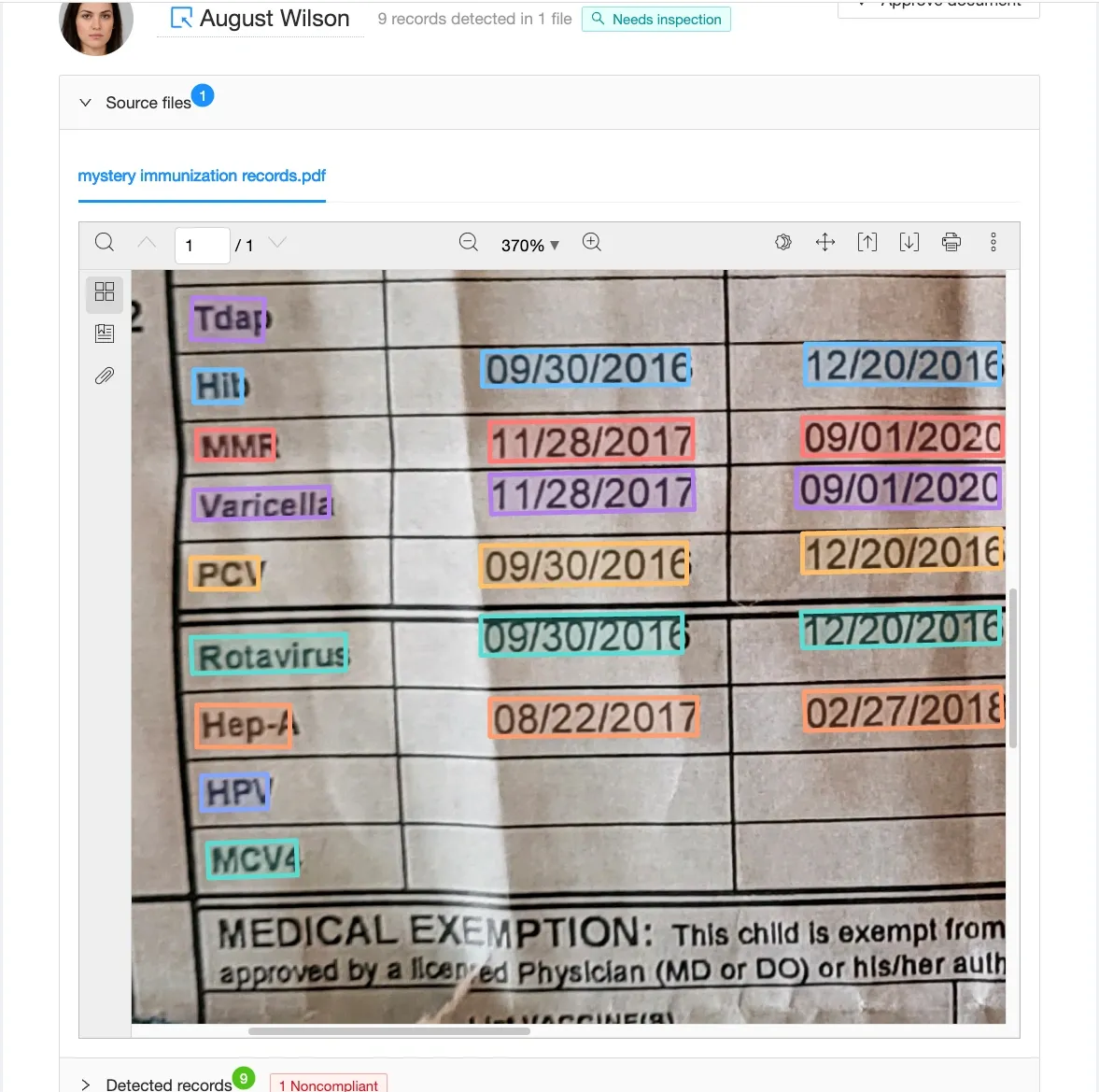
Each square represents a token or segment that the system recognizes.
Classifying characters
Individual letters or characters on the page are found initially via Optical Character Recognition (or OCR). Starting with thousands of hand-written or printed images of each character in the alphabet, we can "train" a classifier. This special function can identify which label (or character, in this case) applies to some given dataset or exemplars
.In machine learning techniques, these classifiers "learn" what each character looks like by a kind of repetitive guess-and-check. After each try, we can use a bunch of calculus to calculate how to change our equations to minimize the chance of getting the same question wrong again. If only life were so easy!
We use this classifier to scan the document and identify all the places where we see individual characters on the page. This process is like combing the beach with a metal detector. Swiping side to side, we follow the feedback of the detector or classifier. When we observe a sharp change in that feedback, we find the local maximum, the place on the plane where the classifier indicates the greatest similarity to a known exemplar. Once found, the contents and location of the match are recorded, and we continue to scan the document.
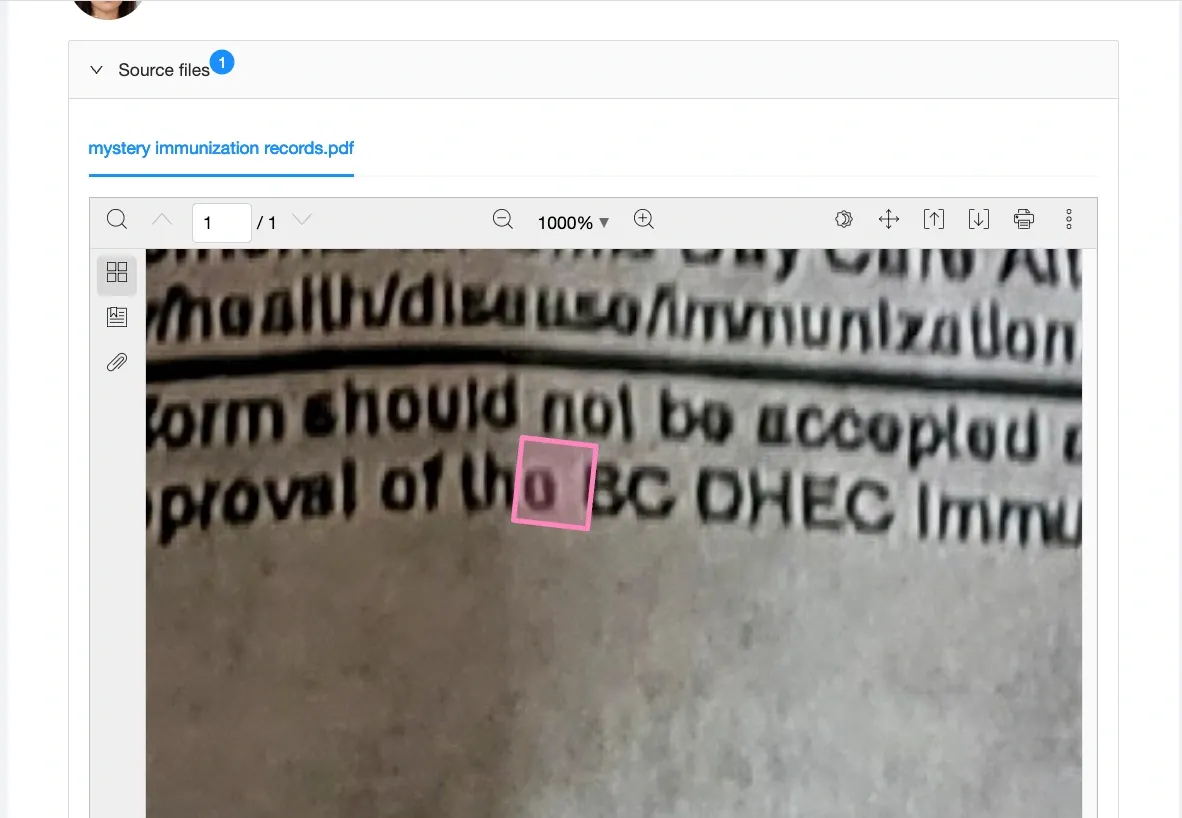
This token represents a single character recognized by the system
After this round of pre-processing, we have a long list of individual characters and the location of each on the page in the form of a bounding polygon. This comprises a sequence of (x, y) coordinates that draw a convex hull around every point in the character, “bounding” the character entirely.
Word segmentation
Having a letter-by-letter breakdown of the document is okay, but computing over that many discrete parts wouldn’t be efficient. Instead, we want to split up the list of characters by grouping letters into words. If we laid out all the characters single file, we could visualize this process as drawing posts between each of the segments of the line.
Our first task is to sort our list of characters into a sequence ordered when each “appears” on the page for a reader in that language. In English, this is left-to-right and down. Simply tracing the same left-to-right-and-down with some nifty geometry is a good start.
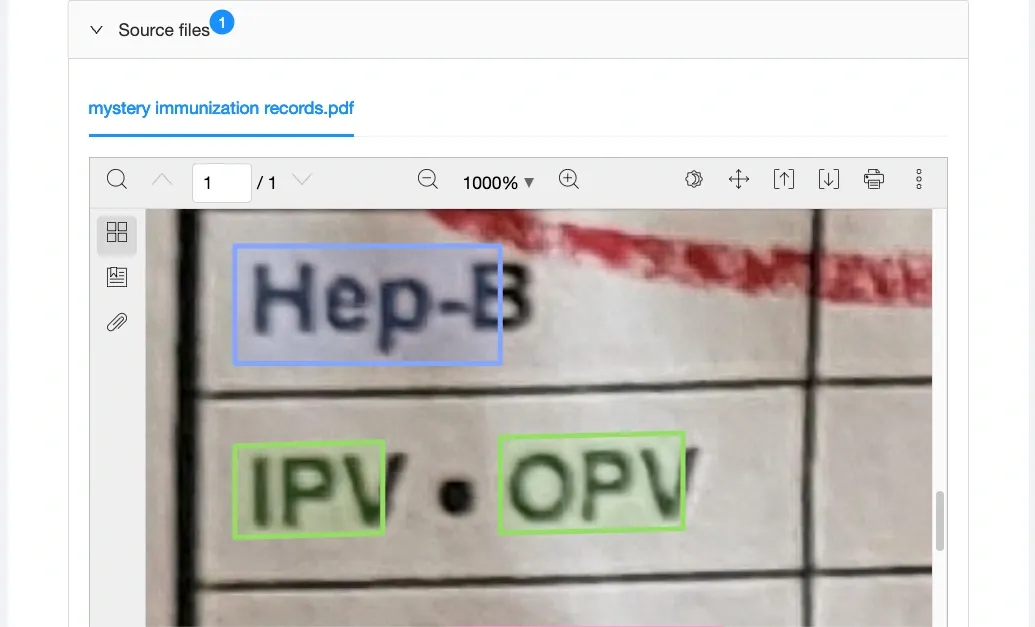
A bullet point is interpreted differently from a dash. Punctuation is one way we can segment the characters correctly.
With our list sorted sensibly, we return to draw our segments. Humans do this intuitively as we read, and different writing systems have evolved different signals in expression. In the left-to-right-and-down of English, we intuit word boundaries wherever we see whitespace or a new line. This makes the space character “ “ a delimiter in English, like the line break.
Our OCR step is designed to capture spaces and line breaks in the horizontal flow of text, but it’s not perfect. A long word may break across lines in tables where the first column contains row headings.

The system may initially recognize words that do not exist because of the geometry of the file
We could introduce additional heuristics around the geometry and relative positioning, but we’ll save that for later. An approach that considers the meaning of the characters as letters is even better.

Varicella and chickenpox are synonyms. Together they can be interpreted as a single meaningful term.
This decade's advances in natural language processing give us many options for evaluating the “quality” of a given sequence of characters. We usually calculate these measures as the probability a sequence of characters represents a complete term.
Deploying a similar process of “mine-sweeping” to the original optical character recognition, we mix this signal together with locations for a more robust view of the linkage between letters.
Text extraction
With a reliable segmentation of detected characters into semantically meaningful tokens, we can produce a more useful reading of the full text of the document.
Returning to our natural ordering of characters, we recall that it was pretty close to what we’d read as the “text” of the document. Now that our word segmentation reflects the semantics of the tokens, line breaks or other strange spacing should already be reflected in the construction of the tokens.
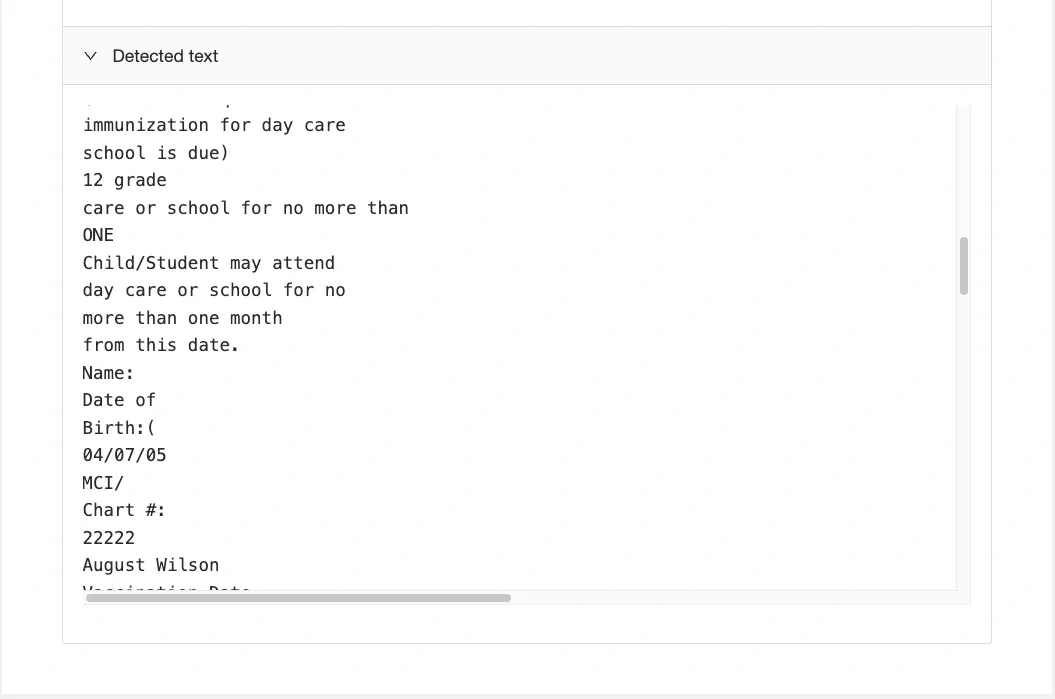
Tracing now geometrically left-to-right-and-down across the page hence exactly mirrors the motion of the eye of the reader. This makes it easy to concatenate the tokens together in the order expected by a human. The result is a readable text.
What's next
After processing the document, we have a list of tokens corresponding to meaningful terms or segments within the text.
Next, we scan the tokens to detect relevant data on the page. We use different techniques to identify specific shot types, dates, and students in a text. Finding many matches in a long document may take a while. To speed things up, we'll structure our scan of the tokens using another classic algorithm.