
Deliverability: Status and failure
Written by Deliverability: Status and failure
02.12.2024
Behind the scenes, we use a constellation of communication networks to deliver messages whichever way we can.
Once we submit a message to one of these networks, we verify that the message is sent along in the right direction. Only when the message reaches the intended destination do we then call the delivery successful.
For this all to work, we must carefully track the status of each delivery as these propagate through the communication networks.
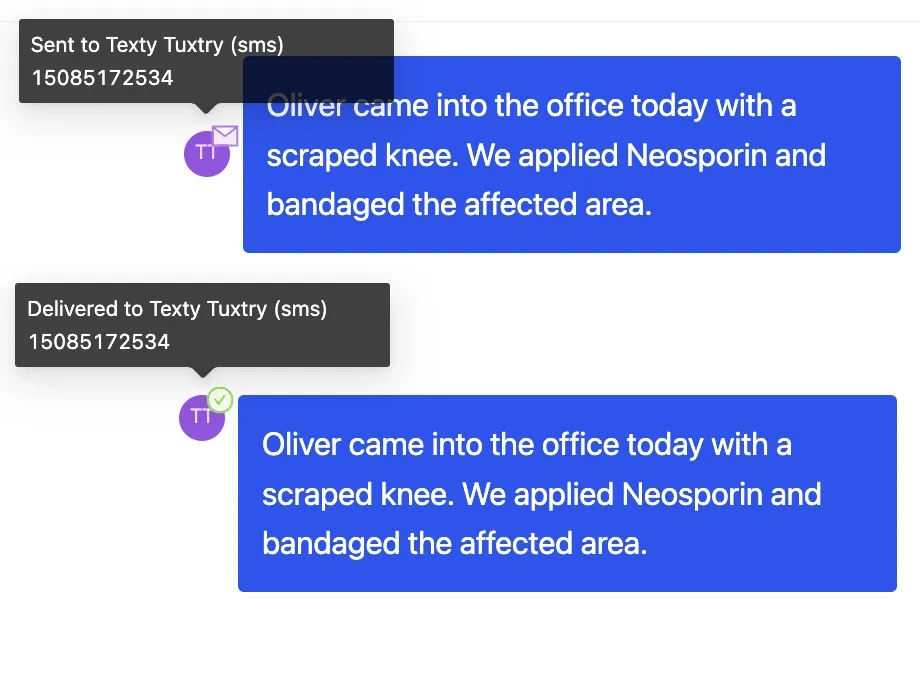
Calling you back
After we’ve tried to deliver a message using some instrument, we listen for updates from the relevant provider about the status of the delivery as it churns through the cloud.
These updates come back to each environment in the form of webhooks. These HTTP requests are sent from the external communication service to each instance whenever some delivery transitions status.
When we hear something new about a delivery we’ve sent, we record the same status on the delivery on our side.
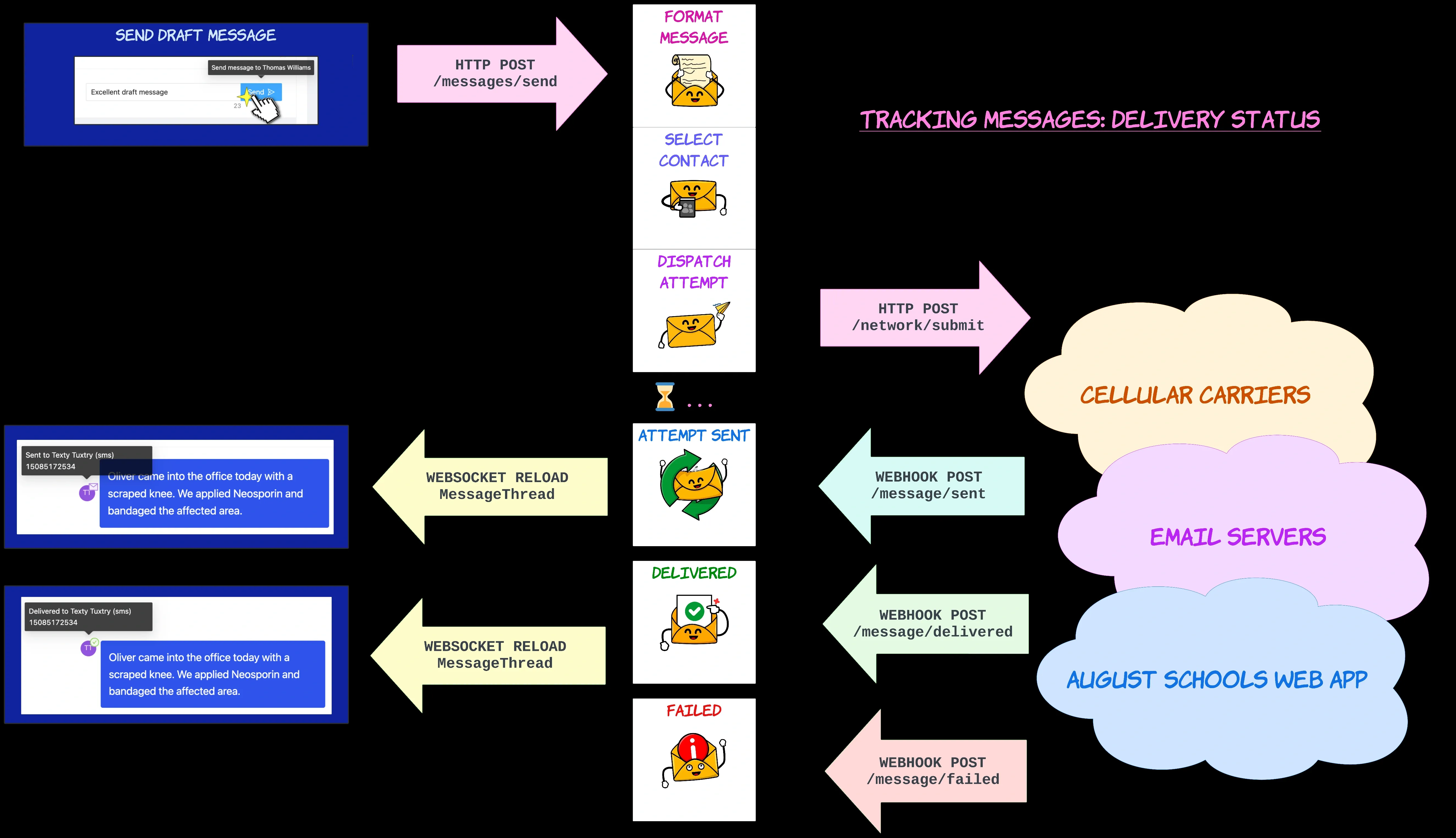
We use websockets to update the UI in realtime as webhooks are received for the active message thread
Once a failure
The most common reason that a message cannot be delivered to a given contact is because their email address or phone number is recorded incorrectly in the Student Information System. This could be a typo or an intentional choice by the recipient.
In these cases, we shouldn’t attempt to re-use a contact method after we’ve already failed to deliver a message to that address in the past.
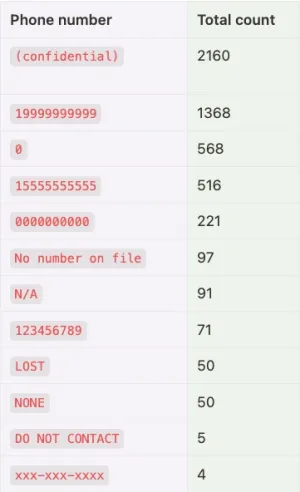
This table lists the most common non-numeric phone numbers observed across our fleet of applications. The system will filter out these and any other implausible phone numbers from consideration as possible contact methods for a recipient.
This approach isn’t perfect, however. The communication networks we rely on are massive, complex, distributed systems that cover over the tangle of domestic and international linkages that pave the information superhighway.

During the COVID pandemic, signal masts installed as part of the 5G wireless rollout became a target of fancy by some on the internet. Fortunately, unlike envelopes, text messages do not burn up in fire.
When something goes wrong in one of these communication networks, we may fail to deliver a message to an email address or phone number for some reason unrelated to the quality of the contact itself. We shouldn’t be afraid to try the same method of contact again in the future.
Instead, we avoid using a contact only when some delivery has failed using that method within the thread in question. If the individual is added to another thread down the road, we’ll try again to use their preferred method of communication. Only when delivery fails again do we exclude that contact method from consideration.
That was fast
Communication networks today are typically pretty snappy.
After we submit a message for delivery, it might take only a few milliseconds for the network to acknowledge and send it along the appropriate connection. It may be just another few milliseconds before the message reaches the recipient and the delivery is confirmed.

Who could have guessed then that milliseconds aren’t enough?
When all goes right with a message, these status webhooks will come in fast and hard. At this level of precision, though, spooky things tend to happen as timelines get all jumbled up.

Time is the real ghost in the machine. Or is it the machine in the ghost? As long as you don’t make me zone time…
Monotonically increasing
Logically, we expect to receive confirmation that our message is delivered only after we hear the message was sent.
What if the order is reversed? In this case, we won’t mark a delivery as sent after we’ve already confirmed delivery with a different webhook. Rather, we treat a confirmation of delivery as one terminal state for a delivery attempt.
Got it on lock
To make the application more responsive, we generally run many parallel threads of execution on the server, each with a copy of the code. That way, the application can service more than one web request at a time, which is critical for our dynamic single page web application.
It also admits the possibility we could receive a webhook that confirms delivery at the same time while we’re processing the webhook that the message was sent. If we’re not careful, the output of either one of these webhooks could overwrite any state intermediate from the other webhook.
To guard against this edge case, we introduce optimistic locking into our webhook handlers.
Getting synchronized
After one of the execution threads receives a new webhook, the application takes a lock on the delivery object. All other execution threads are prevented from taking action on that same delivery attempt until the first thread releases the lock.
If a delivery object is already locked when a second execution thread receives a webhook, then that second execution thread will “block” or wait until the lock is released by the first execution thread.
This technique effectively synchronizes all webhook processing across a single delivery. These webhooks are forced effectively all to execute in serial. In this way, we exorcise many ghosts from our system by minimizing data contention between execution threads.
Next up
Before we can even try to submit a message to the networks, we need to be sure we have the right cloud resources provisioned to actually complete the delivery. These cloud resources are provisioned and recycled automatically as part of the instrument lifecycle.